March 9, 2026 · 10 min read
RAG vs Fine-Tuning in 2026: Which One Does Your AI Product Actually Need?
Most teams pick the wrong approach and waste months. Here's a plain-language decision framework for CTOs and founders — when to use RAG, when to fine-tune, and when to use both.
The two most common questions we hear from CTOs and founders building AI products in 2026:
"Should we fine-tune a model on our data?"
"Or just use RAG?"
Both questions come from the same place — a team that's serious about building an AI product that actually works. But the framing sets them up to make the wrong call. RAG and fine-tuning solve different problems. Picking the right one (or the right combination) is the difference between shipping in 6 weeks and spending 6 months wondering why your AI still gives wrong answers.
This is the framework we use at DevNexus when scoping custom AI development projects. No fluff, no vendor pitch — just the decision logic.
What RAG Actually Does (And What It Doesn't)
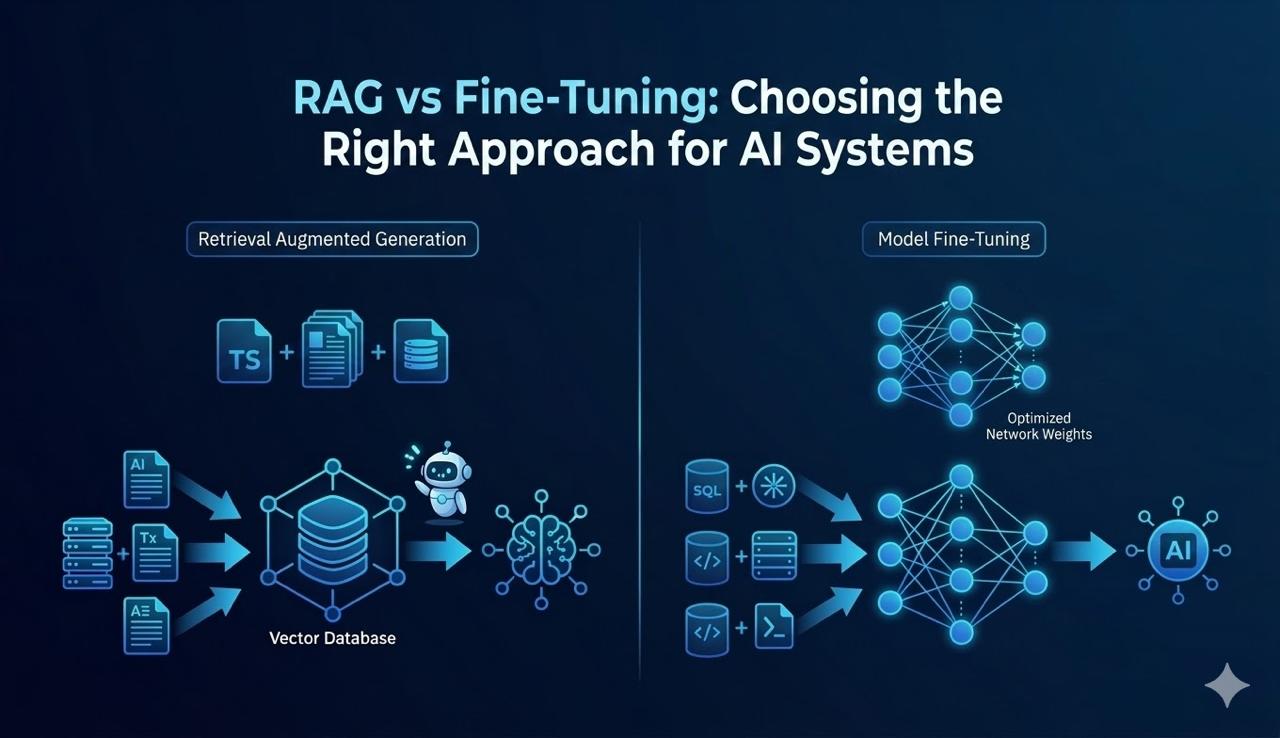
RAG — Retrieval-Augmented Generation — keeps the base model frozen and adds a retrieval layer on top. When the user sends a query, the system fetches relevant documents from a knowledge base and injects them into the model's context before generating a response.
The model doesn't learn anything new. It just gets better context at inference time.
This makes RAG the right call when:
- Your knowledge changes frequently (product docs, policies, pricing, support articles)
- You're working with proprietary data that shouldn't go into a training run
- You need traceable, citable answers (the retrieved chunks are auditable)
- You're building on a timeline measured in weeks, not quarters
And the wrong call when:
- You need the model to behave differently — not just know different things
- Low latency is non-negotiable (retrieval adds 100–500ms per call)
- Your knowledge base is sparse or poorly structured (garbage in, garbage out)
What RAG Looks Like in Practice
A customer support bot for a SaaS company. The bot needs to answer questions about the product, billing policies, and integrations — and that information changes every sprint.
Fine-tuning this model would mean retraining every time a feature ships. Instead: embed the docs into a vector store (Pinecone, Weaviate, pgvector), retrieve the top-3 relevant chunks on each query, and pass them as context. The model stays the same. The knowledge stays current.
We built exactly this for a healthcare AI client. Intake policies changed weekly. RAG let us update the knowledge base without touching the model — and gave us an audit trail for every answer, which was a compliance requirement.
What Fine-Tuning Actually Does (And What It Doesn't)
Fine-tuning adjusts the weights of a pre-trained model on your specific dataset. The model learns patterns, formats, tone, and behavior from your examples — not just facts, but how to respond.
This is a training process. It costs compute time and requires labeled data. But the output is a model that behaves differently at its core, not one that relies on retrieval.
Fine-tuning is the right call when:
- You need the model to output a specific format consistently (structured JSON, a specific report schema)
- You're building domain-specific tasks where the base model underperforms (medical coding, legal clause extraction, code generation in a niche framework)
- You want to reduce inference cost by using a smaller fine-tuned model instead of GPT-4-class APIs
- You have enough labeled examples (typically 500–5,000+ high-quality pairs) to justify the training run
And the wrong call when:
- Your goal is to give the model access to new information — fine-tuning doesn't add reliable factual recall, it adds behavioral patterns
- Your data changes frequently — you'll need to retrain regularly, which gets expensive
- You're pre-revenue and timeline matters more than marginal quality gains
What Fine-Tuning Looks Like in Practice
A voice AI agent that needs to follow a very specific conversation script — exact phrasing for compliance, consistent handoff language, predictable objection-handling structure. You can't prompt-engineer this reliably with a general-purpose model at scale.
Fine-tune a smaller model (Llama 3, Mistral, or similar) on 2,000 example conversations. The result: faster, cheaper inference, consistent behavior, no retrieval latency. That matters when you're running 10,000 calls a day.
The Decision Framework
Stop asking "RAG or fine-tuning?" Start asking these four questions:
| Question | If Yes → |
|---|---|
| Does the model need access to information it wasn't trained on? | RAG |
| Does that information change frequently? | RAG |
| Does the model need to behave differently (not just know more)? | Fine-tune |
| Do you have enough labeled data and budget for a training run? | Fine-tune |
Most real-world AI products will answer "yes" to multiple rows. Which brings us to the part that nobody talks about enough.
The Honest Answer: Most Production Systems Use Both
RAG and fine-tuning aren't competing approaches — they operate at different layers. The mistake teams make is treating it as an either/or decision.
A common production pattern:
- Fine-tune for behavior — Train the model to follow your output format, use your brand's tone, and handle task-specific logic
- RAG for knowledge — Retrieve current, proprietary, or frequently-updated information at query time
Example: A legal document assistant. Fine-tuned to extract clauses in a specific structured format (behavior). RAG-powered to pull from the firm's current case law and contract templates (knowledge). Neither approach alone gets you there.
We used this exact combination building an outreach voice agent on Vapi — fine-tuned for conversation flow and objection handling, with a retrieval layer for prospect-specific context injected at call time.
Cost and Timeline Reality Check
Since we're being direct:
RAG setup (greenfield): 2–4 weeks. Main costs: embedding pipeline, vector database, retrieval tuning, eval framework. Ongoing cost: storage + retrieval API calls.
Fine-tuning (from scratch): 6–12 weeks if you're collecting and labeling data from scratch. Faster if you have existing examples. Main costs: data prep, training compute, evaluation. Ongoing cost: hosting the fine-tuned model.
Both: 8–16 weeks for a solid v1. This is what a genuinely production-ready custom AI system looks like.
If someone tells you they can fine-tune a production-quality model in two weeks, ask to see their training data.
What to Do Before You Decide
The most expensive mistake we see isn't choosing the wrong approach — it's building before validating. Before you write a line of code:
- Define the failure mode — What does a bad answer cost you? A hallucinated medical policy? A missed sales objection? The cost of failure determines how much you invest in the solution.
- Audit your data — Do you have enough clean, labeled examples for fine-tuning? Is your knowledge base structured enough for reliable retrieval? The answer changes everything.
- Run a baseline — Prompt a general-purpose model with your exact use case before investing in RAG or fine-tuning. You might be 90% of the way there with good system prompts.
- Pick the metric that matters — Accuracy? Latency? Cost per query? You can optimize for one well. Optimizing for all three without tradeoffs is marketing copy.
How DevNexus Approaches Custom AI Development
We build production AI systems — not prototypes that impress in demos and break in week two. Every engagement starts with a scoping call where we map the use case to the right architecture: RAG, fine-tuning, agentic workflow, or a combination.
What we've shipped: voice AI agents on Vapi and ElevenLabs, RAG systems on LangChain and LlamaIndex, agentic workflows on n8n and custom orchestration layers. The pattern is always the same — start with the problem, not the technology.
If you're a CTO or founder building an AI product and trying to figure out the right approach, talk to us. We'll tell you honestly whether fine-tuning makes sense for your budget and timeline, or whether RAG gets you there faster.
DevNexus is a custom software and AI development agency. We build AI-powered products for startups and growth-stage companies.
Want to Discuss This Topic?
Book a free strategy call. We’ll tell you exactly how we’d build it — scope, timeline, and what it costs.